Face recognition system based on VisibleLight technology has great performance and reliability, and has the ability to self-learn. Face recognition is one of the most advanced biometric technologies with huge growth prospects in the future. Current technological problems have until recently limited the use of such systems. The main problems of the earlier versions were high requirements for hardware platforms and their performance, for external lighting, camera angles and protection against fake identifications. To compensate for these technological shortcomings, we have developed a completely new face recognition technology, the key feature of which is the use of deep self-learning technology.



Protection against fake identifications (anti-spoofing) is one of the most important tasks of all types of biometric technologies, including face recognition. Using a face photo or video is the easiest and most popular way to authenticate. To protect the system from such situations, we created a software module for detecting a “living” object, capable of self-improvement thanks to self-learning algorithms. Learning is based on exploring the differences between a real person and a photo or video, such as lighting, texture, and resolution.
Rare Trait Classification (SRC) is used to increase recognition speed and to reduce the necessary processing power. This representation uses the mathematical linear characteristics of neighboring pixels and a self-learning algorithm for distinguishing features. Using optimized algorithms allows identification in less than 1 second.

Face recognition is usually carried out in a dynamic environment where the intensity of light sources, viewing angles and distance to the camera change. Self-learning technology allows the system to independently extract and filter characteristics to study differences at different distances, postures, viewing angles and brightness of light sources. This allows you to extrapolate and improve the original image, even if the distance, lighting and angle are less than ideal. The system can work even in low light levels.

Traditional face recognition goes through four main stages: detection, alignment, feature extraction and recognition. Advanced face recognition in visible light includes several additional steps to complement this technology.
DetectionThe system will first determine if there is a face in the image or video. During detection, the program with high accuracy allows you to find faces regardless of their size and ambient light. | |
Pose definitionAlgorithms for determining the position allow you to accurately determine the three-dimensional angles of the object. Accuracy is especially important for further 3D image restoration. |  |
Quality analysisAfter evaluating the posture, the brightness and clarity of the image will be analyzed to ensure that quality falls within the acceptable range and to weed out images that are classified as unrecognizable, to prevent loss of processing power |  |
AlignmentAlignment of the face is the positioning of the eyes, nose and mouth of a person in the specified framework. This process uses 2D transforms, including motion, scaling, and rotation. Aligned images are more effective for identification. |  |
Feature extractionFurther, a special algorithm analyzes the image, examining neighboring pixels, forms curves, finds edges, determines shapes. After that, we can get a set of specific features specific to a given person and perform a comparison with existing patterns. |  |
Unlike a “living” human face, the face in the photograph moves with the entire photograph, including the background of the photograph. Given this feature, the program first captures the video sequence and analyzes adjacent frames, selects facial contours and analyzes the behavior of pixels on the border in time, which makes it possible to understand whether a real background or photograph is used.


Self-training helps to identify the differences between a living human face and video. The texture and resolution, surrounding objects, background image, etc. are analyzed, which allows you to detect the frame of a smartphone or tablet and to identify an attempt to false identification.

Recognition is a process that classifies the received data with the given identifiers by cross-checking the extracted patterns with patterns. Recognition is usually done for training or for identification:
After entering the data for training and the corresponding face template, the program will begin studying, restructuring it into pixels to form curves, edges, shapes. In addition, a comparison with a set of training data, which can vary in angle, position, distance and lighting, allows the system to find the difference between them, and find a way to expand the range in angular distance and make more accurate and effective identification.

The recognition task, as a rule, can be divided into two: a 1: 1 check and a 1: N comparison. Person recognition comes down to the processing of the received data by classifiers. Classifiers or classification method will significantly affect the quality of recognition and processing time. Rare trait classification (SRC) is used to increase efficiency by minimizing the amount of data being processed, which reduces the processing power of the system and reduces processing time.

Advanced face recognition is an advanced technology that can perform a variety of face recognition tasks in a dynamic environment.

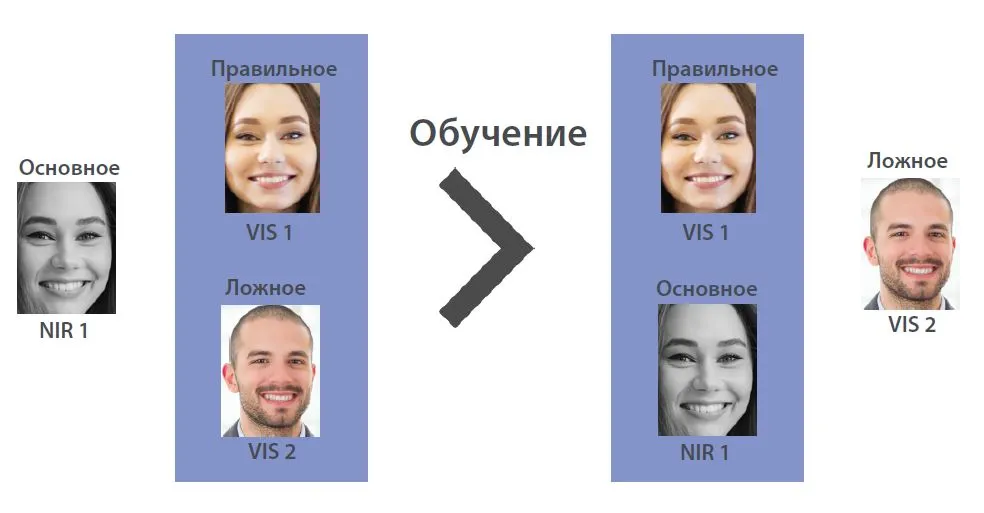
We are currently developing a multi-modular technology for face recognition based on near infrared (NIR) and visible spectrum (VIS). The self-learning module selects the NIR image as the primary, and two VIS images as optional: one correct sample and one false sample. Selecting the NIR image as the base image and using the triplet for training will further reduce the difference between the base and the correct sample and easily distinguish a false sample.
 Shopping Cart0
Shopping Cart0 Project Consultation
Project Consultation Back to Top
Back to Top
 Software
Software  Equipment against COVID-19
Equipment against COVID-19  Time Tracking
Time Tracking  Video survelliance
Video survelliance  Shop equipment
Shop equipment  Biometric Performance
Biometric Performance  Security inspection
Security inspection 










